Typically less than 1 − 2 % of the collected images from benthic surveys end up being annotated and processed for science purposes, and usually only a subset of pixels within each image are scored. This results in a tiny fraction of total amount of collected data being utilised, O(0.00001%). We have a number of research projects targeted at leveraging these sparse, human-annotated point labels to train Machine Learning algorithms, in order to assist with data analysis.
A superpixel-based framework for estimating percentage cover
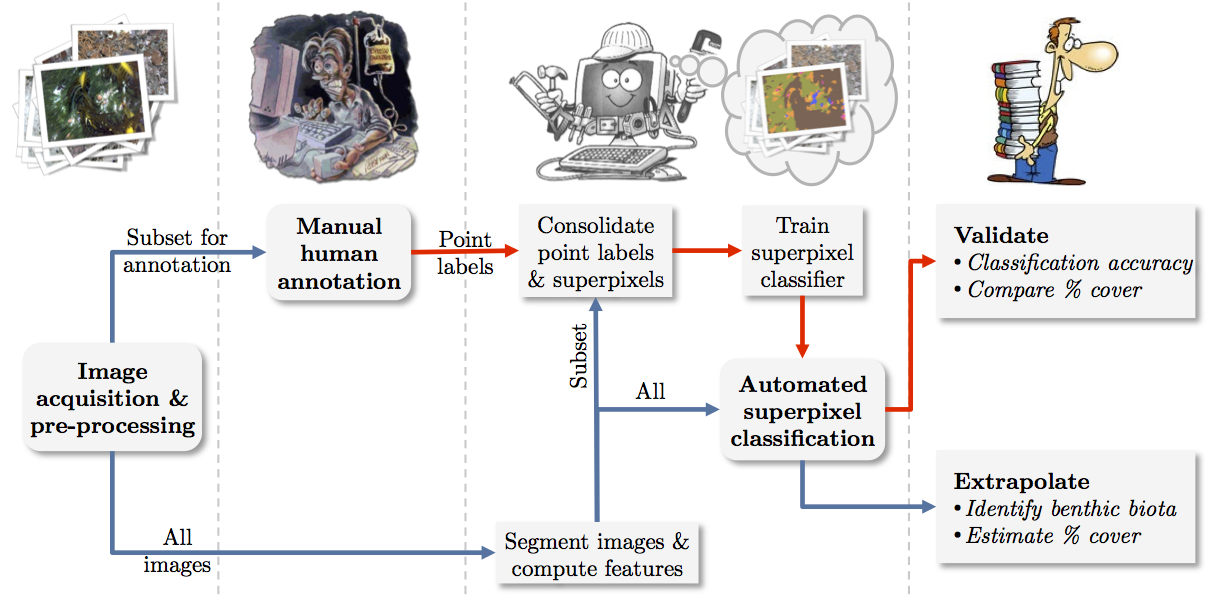
The following provides a brief overview of a superpixel-based framework that can be used to efficiently extrapolate the classified results to every pixel across all the images of an entire survey. The proposed framework has the potential to broaden the spatial extent and resolution for the identification and percent cover estimation of benthic biota.
The following animated diagram provides an overview of the system:
Segmentation offers some notable advantages over defining a fixed shaped and sized pixel patch for classification. For example, if a patch is positioned over a boundary between two class types, it may be difficult to determine the class label assignment, which may confound the data used for training and prediction. The figure below shows an illustrative example of this.
It is evident that the resolution of the classification results may also be limited by the choice of patch size and the resolution of patch positioning. Large patches may contain multiple classes making it more difficult to assign a single, specific class label and small patches may be difficult to classify as they lack context. These factors affect both the ability to classify and the resolution of the classification, which in turn may confound statistics, such as percent cover, which will be computed from the classification results. Examples of images classified using the superpixel framework are shown below.
In the image below, we can see the spatial layout of the classifier estimates vs the manually labeled points. The results show good correspondence between manual label estimates (black circles) and automated estimates (filled circles). In addition, the results appear to make sense scientifically: deeper regions are dominated by sand and the photosynthesising classes tend to be limited to the photic zone ( < 60m).
The classification results can also be used to query unannotated data. The image below show example images that have been extracted from the unlabelled data.

For more information refer to Chapter 6 of Ariell Friedman’s PhD thesis:
Automated Interpretation of Benthic Stereo Imagery. Ph.D. Thesis, University of Sydney, 2013.